AI SOBERING 2023: DATA CENTRICITY NEEDED FOR THE NEXT STEP IN AI MATURITY
To date, 63% of companies are still in the experimentation phase with AI, and 80% of all AI projects are still stuck at the Proof of Concept level. These are sobering statistics. Wouldn’t you agree?
In this article, I will update the insights I presented in my 2020 AI Sobering blog and explain why data quality is now getting so much attention and importance. I will also sketch the steps organizations can take towards ensuring organization-wide reliable data and provide some key recommendations on how to get started from where you are on your journey to AI maturity.
DOWNLOAD PDF FOR FREE
#DATA AND AI ARE EATING SOFTWARE
In 2011, Marc Andreessen famously claimed that “Software would be eating the world.” He also predicted that software companies would disrupt traditional industries. Since then, we have seen many industries transform. Following the lead of Amazon, Netflix, Airbnb, etc, numerous companies have started using their data to their advantage. However, from what we have observed today, I believe that it is instead “AI and data that are eating software”.
And this is because most companies have become not only software companies but also data companies that use their data as strategic assets to compete in their respective markets. This shift to data-driven decision-making, advanced automation, and AI models in production (at scale) is necessary to remain competitive. Of course, not all industries are developing at the same pace or are under the same pressure; however, it is for sure happening.
#AI SOBERING DEFINED
During my period working in venture capital, I had over 200 conversations with AI companies. From these talks, I started to see a trend that I later called AI Sobering. I called this trend “AI Sobering” because I noticed a huge discrepancy between the expected outcomes and the actual outcomes of the AI initiatives of these companies. That the state of the AI market is sobering is not entirely a surprise. A lot can be linked to where AI is on the famous hype cycle of innovation (produced annually by Gartner). Over the years, AI as an umbrella topic has broken up into several smaller segments, each with its own maturity level.
For example, today Big Data is perceived as mature and productive by many, but back in 2014, it was still going through the trough of disillusionment. As you can see in the figure below, every innovation that survives, once started as a technology trigger. Then these become hyped up to a peak of exaggerated expectations to eventually evolve to a plateau of productivity after moving through the trough of disillusionment. Sobering up is part of becoming mature...

Now, two years after my initial AI Sobering article, my key conclusions have remained almost unchanged: Most companies are still experimenting with AI, and most of the earlier flagged findings are still valid. I made these conclusions by studying a recent Accenture survey which was conducted with over 1,600 C-Suite executives and data-science leaders from the world’s largest organizations. Below are some of the observations from this report that led me to my conclusions:
80% of all AI projects are stuck[1] at the Proof of Concept.
50% of all AI projects fail due to poor data quality (for one out of four companies according to International Data Corporation (IDC)).
90% of VC-backed AI companies end up as services-oriented organizations because they never evolve to 80% productization[2].
Much of what is labeled as 'artificial intelligence’ today is not AI at all.
So it begs to question: What are the reasons that so many (VC-backed) AI start-up companies fail or never achieve full productization? Here is what I think:
They have no focus: They serve too many non-related use cases and subsequently try to cater to the needs of too many user personas (A one-size-fits-all approach is rarely successful.)
They cannibalize use cases: They do not break down the problem into smaller bite-size problems that can be solved separately in a scalable and ecosystem-friendly method. Solving a use case end-to-end is often not feasible.
[1] https://www.accenture.com/us-en/insights/artificial-intelligence/ai-maturity-and-transformation?c=acn_glb_aimaturityfrompmediarelations_13124019&n=mrl_0622
[2] Based on personal research during VC period.
They use non-scalable AI models: They cannot replicate models to a similar asset so moving to the next ‘asset or device’ would require a lot of tuning or additional services.
They have an unhealthy unsustainable gross margin: They use a cloud infrastructure that is substantial and that sometimes has hidden costs. They also rely too much on the “humans in the loop” to function at a high level of accuracy.
Even given these reasons, it’s good to note that overall AI maturity is increasing but still strongly varies between industries. The expected forecast for 2024 is promising, though. After reviewing the data from the 2022 Accenture Survey mentioned above, here are a few more observations I’ve made:
Only 12% of companies are already AI achievers.
The automotive industry is the pack's leader if we exclude ‘big tech’.
The chemical industry is lagging against the industrial average.
And very important to mention: According to Accenture, AI transformation is expected to take less time than digital transformation, approximately 13% or 16 months faster.
#BARRIERS TO AI ADOPTION
AI has been a technology buzzword for over a decade now; however, if only 12% of companies out there are real AI achievers, what’s preventing organizations from making the next step in AI maturity?
To formulate an opinion about this, I would like to reference an annual study O'Reilly conducts on barriers to AI adoption.
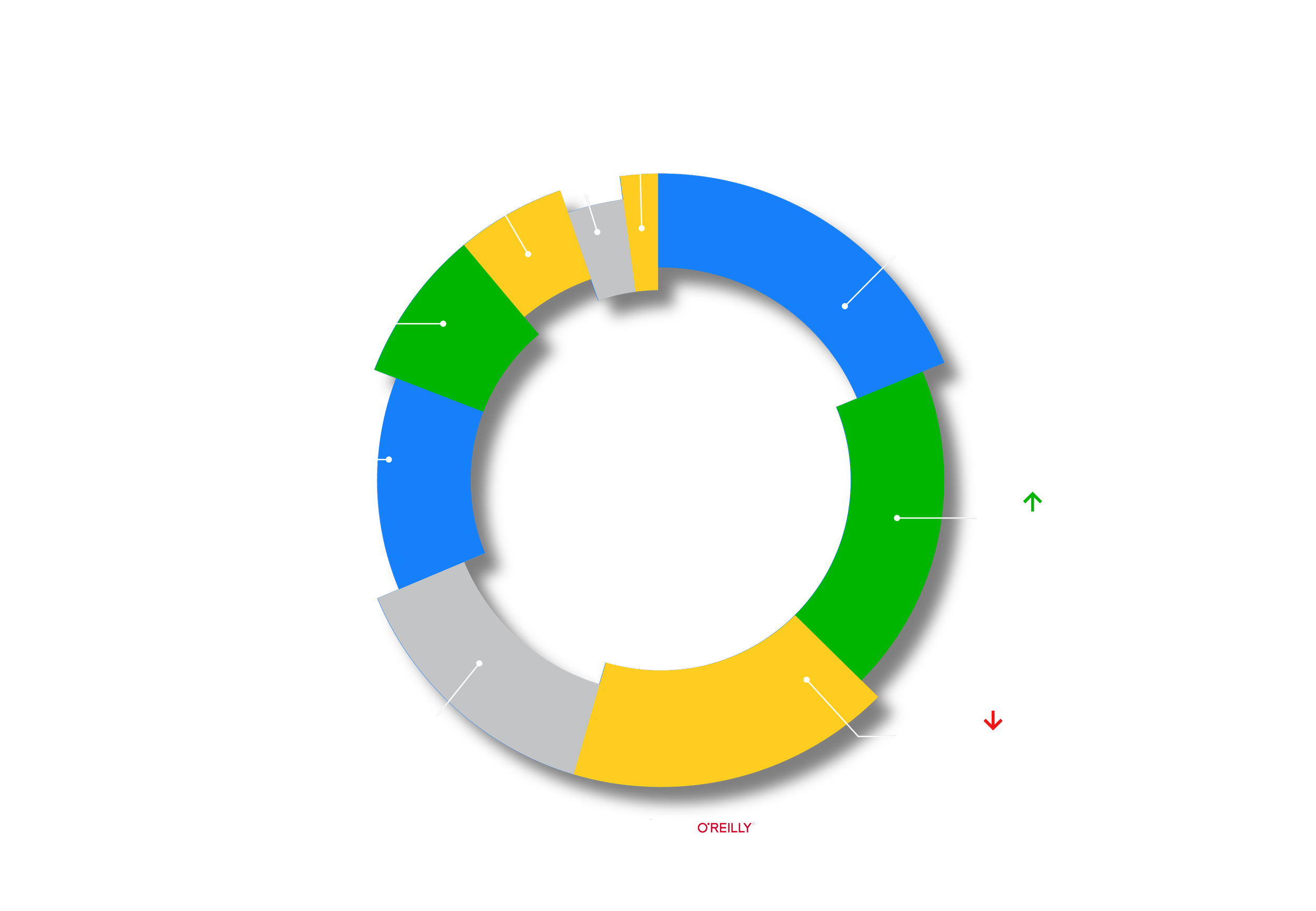
Referring to the figure above, and compared with previous years, the same challenges exist today, but there are some important trends and changes. The three aspects contributing to nearly 55% of current barriers are the “lack of skilled people or difficulty hiring the required roles”, “difficulty identifying appropriate business use cases”, and “data quality issues or lack of data quality”. I have several observations about these challenges and about moving toward a more mature AI practice.
#1. At 19%, the “lack of skilled people or difficulty hiring the required roles” is the highest scoring barrier. To overcome this challenge, organizations need more business users or citizen data scientists - a term we use to describe subject matter experts who have increased their data science knowledge and experience. Furthermore:
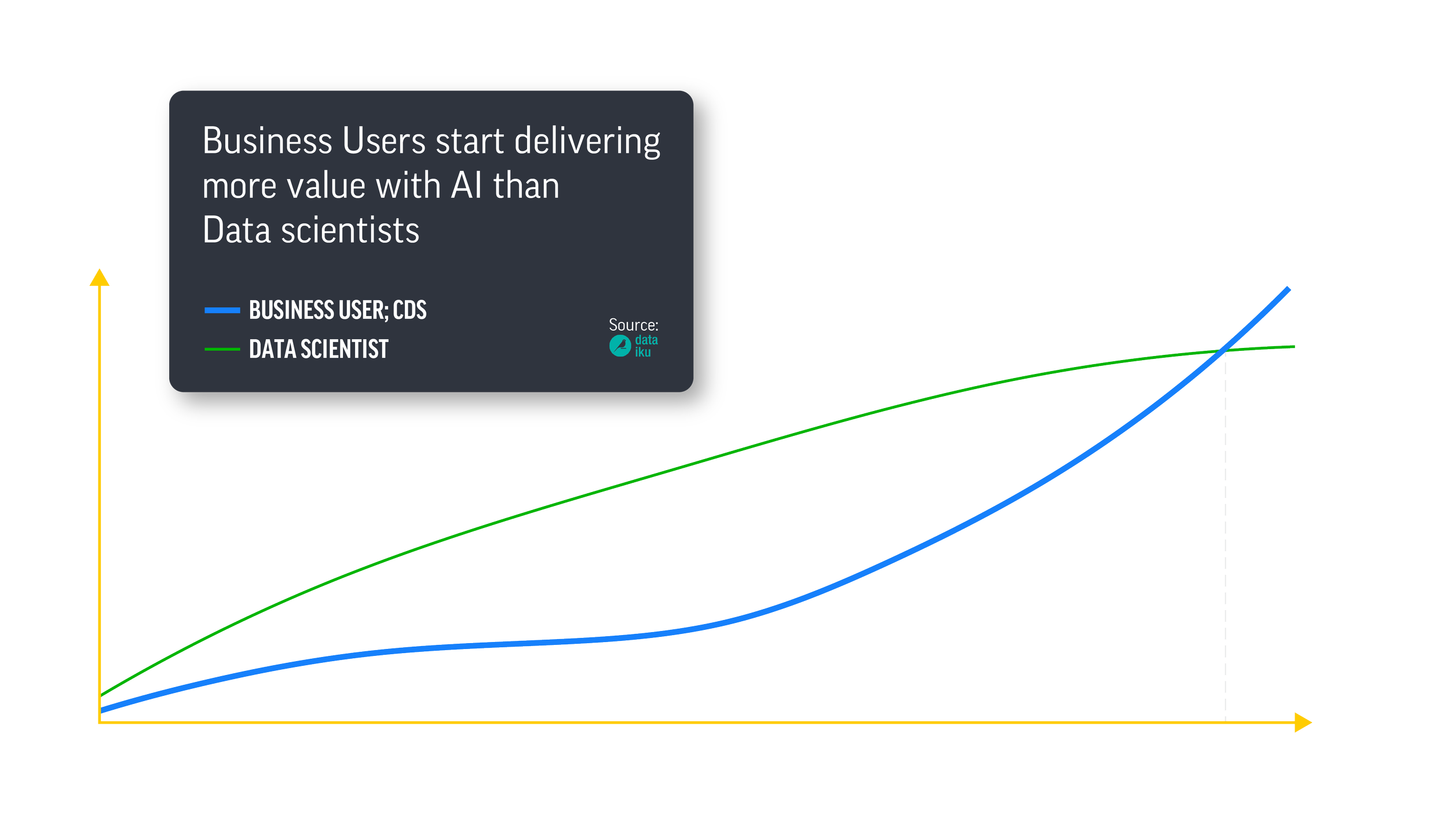
There is simply a global shortage of data scientist profiles in the market. Therefore, for organizations to succeed in their overall digital transformation, they need more internal hands working with the data, i.e., business users or citizen data scientists (see figure below).
According to a 2022 study from Dataiku, we are at a crossroads because these business users and so-called citizen data scientists have started delivering more value with AI than data scientists. A key recommendation here is to hire people that are passionate about the problem, not just about the ML techniques that can be applied.
#2. The “difficulty identifying appropriate business use cases” at 17% is a second barrier to AI adoption. However, as I mentioned above, since there is an increased number of citizen data scientists and business users, there will also be a resulting decrease in the difficulty of finding and identifying appropriate use cases.
#3. A third barrier is the “data quality issues or lack of data quality”. It is striking to see that when moving into a more mature AI practice, the importance of data quality starts to play a more dominant role. This number has increased from 12% to 18% in less than a year, and I expect this number to grow in the coming years to become the most dominant contributor to AI maturity. Therefore, it is time to embrace the fact that to make the next step in AI maturity, organizations need better data, not better models.
What this means is that companies need to guarantee trust in the data that resides in all the data stores out there and to make reliable, trustworthy data available to an ever-growing number of data consumers. Additionally, “Data is a strategic asset” needs to be more than a CXO buzz statement. In fact, if data is used at scale while the trust in that data cannot be guaranteed, then data becomes a liability. Thus, if organizations truly want to become data-driven, then data reliability is an absolute prerequisite.
#THE GREAT UNLOCK & THE IMPORTANCE OF DATA QUALITY
Why is data quality suddenly so important? Wasn’t this an old Gartner quadrant? Yes, that’s a right observation. More than two decades ago, the first-generation data quality platforms entered the market shortly after the first-generation business intelligence and data warehouses came to the market. The first movers such as Precisely, IBM, Informatica, and Talend are still important today in this market and are highly profitable.
However, due to technological evolutions of recent years, organizations can now store and compute data at scale (mainly in the cloud), freeing up people giving them time to focus on higher-order technology like ML/AI and better tooling. With these new capabilities, organizations have started building data-driven applications that are mission-critical. This is called ‘the great unlock.’ In fact, the leadership of many organizations promote this evolution by encouraging their employees to work more with data in their transition to becoming more data driven. Hence, with a growing amount of data consumers, trust in data has become crucial for success.
The big difference between the established, first-generation data quality/observability vendors and the second-generation data quality/observability vendors like Monte Carlo Data, Soda, Timseer.AI, and Databand is that these “new kids on the block” are natively integrated with all the new building blocks of the modern data stack: data integration tools, ETL/ELT, data transformation, metric stores, and many more. And these vendors offer end-to-end data observability as a core differentiator.
I predict that data quality will soon become the fastest-growing category within enterprise data. Since companies like Databricks, Snowflake, and Google BigQuery are all posting revenues above $1B, this is a significant indication that the data quality/observability market will become business-critical and huge. Let me explain: The tremendous revenue of these companies indicates that there will be further adoption of modern cloud data stores since the faster the revenues grow, the more the adoption of modern cloud data stores will grow. More importantly, all this data needs to be protected and guaranteed that it is reliable. Companies have been investing heavily in their data infrastructure over the last years, so it is a logical consequence that data leadership needs to protect the data that resides in their data stores and that is heavily used. Right?
#RELIABLE DATA: IT’S EVERYONE’S PROBLEM!
The evolution towards mandatory reliable data needs to be supported by the CDO offices or the data governance teams. No one wants to and should serve as a company's designated 'data janitor’ - the person responsible for cleaning the data. As such, let’s have a look at each entity’s current pain regarding this issue:
Chief Data Officer:
Providing trust in data is shifting towards corporate responsibility, especially given that today a growing amount of data consumers rely on the available data, and only a small percentage of these consumers is aware of the quality and reliability of this data.
Data Teams (Data Science + Data Engineering):
These teams are acutely aware of the importance of data quality and spend as much as 60% of their valuable time on cleaning and transforming data: a time-intensive, manual job no data scientist enjoys and by default is usually tackled at the end of the data pipeline (which is too late).
Data Quality should be everyone's shared responsibility, yet in many organizations, data engineers are expected to clean the data and maintain or fix pipelines they didn't break in the first place.
Business Users:
When unverified data is used for day-to-day decision-making, in key operational Excel sheets, and for troubleshooting, it’s just a matter of time before wrong decisions are made and wrong insights are derived. Obviously, when the quality of data is not known, the accuracy of decisions is also not known. The impact of this can be enormous.
The Business Itself:
For many business processes, as long as there is a human in the loop, there is always the possibility of error. However, if organizations truly shift towards ‘autonomous operation,’ data-driven decision-making and advanced automation, data quality shifts into a “must-have”. There is no possible autonomous operation without reliable data.
#SIZING THE PROBLEM OF DATA QUALITY
The size of this problem will only keep growing, and I believe this for several obvious reasons:
The amount of ‘new’ data will continue to grow. In fact, 90% of the world’s data has been generated over the last two years. In an industrial context, this data growth has accelerated due to the advent of 5G and the rise of cheap sensors.
The enterprise data stack is becoming increasingly complex, so as a consequence, with each step the data takes upstream or downstream in the data pipeline, the impact of data downtime balloons.
Since data is increasingly leveraged and used, data downtime will impact more critical business processes, services, and products.
“Data Downtime: Refers to periods of time when your data is partial, erroneous, missing, inaccurate, or where the integrity can’t be assured.”
#MAD* MATURITY MATRIX ™ AND DATA THAT BECOMES A LIABILITY
Another piece to this puzzle is understanding the MAD Maturity Matrix and how unverified data can become a liability. So first, let’s start with the MAD maturity matrix. As seen in the two-dimensional matrix below, the maturity of data quality is plotted against the maturity of AI/data. To indicate the maturity of the AI practice, we distinguish five levels:
Basic: Investments are made in data storage infrastructure and the first dashboards are up and running.
Foundation: Discovery analytics (search/troubleshooting tools) are present, and the organization has dedicated people who can be labeled as citizen data scientists.
Operational: The company has matured into predictive analytics and has some first AI/ML proof of concepts running, and next to the CDS teams, there are data scientists/engineers amongst the workforce resulting in full operational data pipelines.
Systemic: The company is scaling up its AI practice and has the first predictive models in production and is investing heavily in further cloud transformation.
Transformational: The organization has evolved into storing their data in the cloud and is working on digital twins and has predictive production analytics models at scale.

Referring to the figure above: If organizations advance their AI/Data Maturity (X-axis) without paying the proper attention to data quality, data becomes a liability. Digital transformation will only be successful if the generated and stored data is reliable. Whenever an organization is confronted with one of the following symptoms, there is likely a situation where data has become a liability:
Limited or no repeatability and scalability of AI models
Lack of trust in the data-by-data consumers or lack of trust in the predictions made by the model
Clear evidence of data downtime that has resulted in operational downtime
Suboptimal data-driven decisions
Extremely low efficiency in data projects
Difficulty in moving beyond the POC level
As you can see, for many reasons, data reliability is a business-critical issue, and the size of the problem is growing. I have already mentioned several reasons for this, but let me weigh in on a few more:
Most data stored today is unmonitored, unstructured, and unverified for reliability.
Ninety percent of the workforce is ignorant or unaware of the quality of data.
Nearly every data consumer will agree with the fact that they have data issues, but nobody knows the size of this impact.
Hence, the impact and size of data quality are unquantified today, and consequently companies are vulnerable at scale.
#HOW DATA CAN BECOME A STRATEGIC ASSET
I hear a lot of CDOs and data decision-makers say that data is a strategic asset. If data is truly this, and thus more than just a buzzword, organizations must treat it as such. If they mean it, they must handle it accordingly. However, this will never happen if they push through with a sole focus on AI maturity without concentrating on ensuring the quality and reliability of the data. Proper data quality management and observability are imperative to move towards full AI maturity and to achieve this impact at scale. Of course, this only works in steps which I’ve outlined below and that are illustrated in the figure that follows:
Step 1: Provide tooling to be able to assess or score the quality of the data.
Step 2: Enable the capability to monitor the quality of data over time and flag anomalies and provide the first triage capabilities.
Step 3: Provide the ability to set up data quality SLAs (and monitor against them) and provide a data cleaning pipeline/data service to provide optimal quality.

Data can become an asset if we move linearly towards the upper right quadrant, where organizations will be both optimized for data quality and transformational with AI. As an organization, if you are on the right track, here are a couple of common outcomes to detect:
Organisational trusted data and decisions
Repeatable, maintainable, and scalable analytics
High useability by all data user personas
Reduced time to value
To conclude, I want to share some key conclusions and some key recommendations on how organizations can more quickly arrive at the AI productivity plateau.
#KEY CONCLUSIONS
Organizations need to accept that the bottleneck is the data, not the state of the models used today (which corresponds with what thought leaders like Andrew NG are saying).
Only 12% of the companies out there can already be labeled as AI achievers. However, it’s expected that AI transformation will take less time than digital transformation.
Data cleansing and contextualization are done and tackled often at the end of the data pipeline. As a result, data teams lose valuable time discovering the reason(s) for data anomalies.
Data quality is not yet omnipresent in most organizations that leverage their data. I think after reading this article post, it’s clear that this is not just the problem of IT or the data teams.
#KEY RECOMMENDATIONS
Organizations should make data governance a corporate strategic topic for all their companies, making not only the IT data (relational data) a scope or focus but also the operational data.
Organizations need to equip data science teams with the right data engineering/operations tools to boost and optimize their productivity, so they can save time on data cleaning and transformation.
Organizations need to invest further in creating more business users and citizen data scientists (domain experts). This step will result in many more hands that can contribute to the success of the organization’s digital transformation.
Organizations must start quantifying the quality of data and monitoring the quality of the data over time to get a better understanding of the size of the current problem and to take the first step towards data centricity.
Organizations should start by appointing data stewards (internal promotion). These are subject matter experts that understand both the business/operations and the content of the data and are responsible for ensuring the quality and fitness of the organization's data assets.
Organizations should clean and contextualize the data closer to the source since these people understand the operational context and the content of the data. Too much time is lost finding out post-mortem what is wrong with the data.
Organizations should establish the good practice of working toward one single version of the truth regarding data. However, it should be noted that it is good practice to store several tiers of aggregated data with different data quality levels (Bronze/Silver/Gold, as seen in the figure below).
Organizations should create and expose Brown Data (dirty synthetic data by design) with available data products to expose vulnerabilities which will lead them to understand what data defects they need to protect themselves from. This is good practice. Even if issues haven’t happened yet, it doesn’t mean organizations are not vulnerable.
Organizations should invest heavily in using data while assuring a reliable foundation, and as much as possible, should create mission-critical data-driven applications. After all, the above recommendations only matter if data is used more in dashboards and data products and if it triggers workflows and tasks to generate actionable insights.
To end, all of the above recommendations are relevant only if organizations first start using data more, so to reiterate: “Do more of recommendation #9”. 😊
This list is limited, and there are many more recommendations to give. So feel free to share your opinion/take on this. I can elaborate on these in my next blog post if needed.

#TIMESEER.AI’S ROLE IN ENSURING THE SUCCESS OF AI MATURITY
I represent Timeseer.AI as its co-founder and CEO. We have developed a Data Quality Management and Observability Platform for time-series data which is includes sensor/device data, timestamped system metrics, financial stock data, and weather data.
The time-series space is booming! It has been the fastest-growing database segment for the past 2 years and will continue to grow. It’s important to point out here that most 2nd generation data quality tools available today are built and optimized for relational data. These tools do not work well for time-series data since time-series data is a completely different animal. (I’ll elaborate more about this in a later blog.)
By focusing on time-series data, we are making a contrarian bet on the absolute need now and in the future for a data quality management and observability platform for this data type. And we estimate, although possibly a bold prediction, that by 2030, ALL sensor data stored in time-series databases will be monitored for reliability to ensure that the data is fit-for-purpose and can be treated as a true strategic asset.
As Timeseer.AI, we have outlined our mission on two levels:
On the enterprise level, we aim to reduce the number of data quality and sensor data integrity incidents that hit operations by 10X.
On the individual level, we aim to help bring in 50% extra productivity in the daily sensor data ops for data science teams.
#ABOUT ME
After Software AG acquired my previous software scale-up company, I worked for three years as a partner at Smartfin Capital, a European technology Venture capital fund. During this time, I had the opportunity to investigate and study the entire market with a sole focus on IoT and MAD (in other words: “machine learning, AI, and data” as venture capitalist and owner of the MAD landscape Matt Turck started calling it).